In a world of multi-core processors, memory caching can break useful abstractions.
Tags: position concurrency hardware abstractionsIt seems Moore’s Law will remain an accurate model for predicting transistor density in processors for the immediate future. However, Dennard Scaling is widely recognized as broken. The result is that exponentially more transistors are packed into processors yet processor performance increases sub-exponentially.
Due to this, the additional transistors are being used to facilitate parallel computation pipelines in the form of multi-core processors rather than to improve processor performance. Naturally, software should try to leverage this parallelism. However, writing software to take advantage of parallelism exposes details of the processors that were previously hidden in a single core processors. Specifically, I am thinking of detail related to memory caching.
Single Core Processors: When caching only affected performance
When Dennard Scaling was not broken, exponential transistors would translate to exponential improvements in single-core processor performance. However, instructions involving reads and writes to memory add delays to maximum performance as memory access is slow with respect to single-core processors. A primary strategy for speeding up memory access is caching. The idea behind caching is very simple: keep data that is likely to be accessed in the near future in small, fast, and very expensive portions of memory, i.e., “higher” cache levels, and when done with them move that data to less expensive but slower memory, “lower” cache levels.
It is important to note that caching may result in incoherent views of data. Data is typically only written to lower cache levels when higher cache levels have exhausted their capacity. In a single-core processor setting, this inconsistency is not detectable; memory is queried for a particular address from highest cache to lowest cache (this explanation is simple but not entirely accurate, queries cascade down cache hierarchies and relevant data climbs up the cache hierarchy via these cascading queries).
In effort to make this clear, the following diagram is provided:
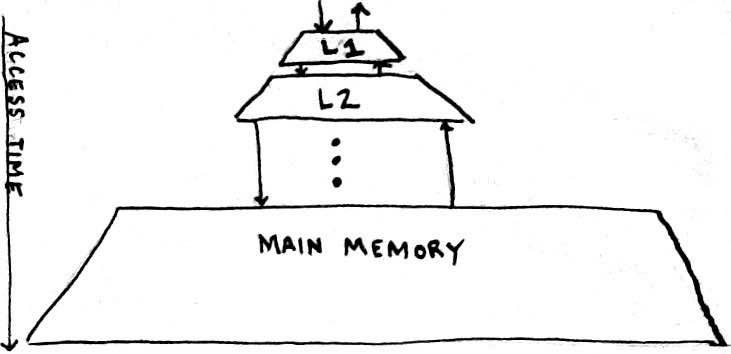
An arrow pointing down out of a cache level represents an access query being passed down the hierarchy because the requested address was not found in the current cache. An arrow point up into a cache represent that data was eventually (a miss could have first occurred causing a request for an address from the a lower cache level) inserted into the current cache. The insertion may have caused other data to be evicted from the current cache. Typically, if evicted data has been modified, then it is written into the lower cache level. In general, the further down the cache hierarchy some cache is, the longer a query will take; this is the intuition that should be extracted from the access time arrow pointing down on the left of diagram.
Multi-core Processors: Now caching can affect program semantics
As Dennard Scaling failed, processors with multiple cores proliferated. Multi-core processors have more complex memory hierarchies that resemble something like the following diagram:
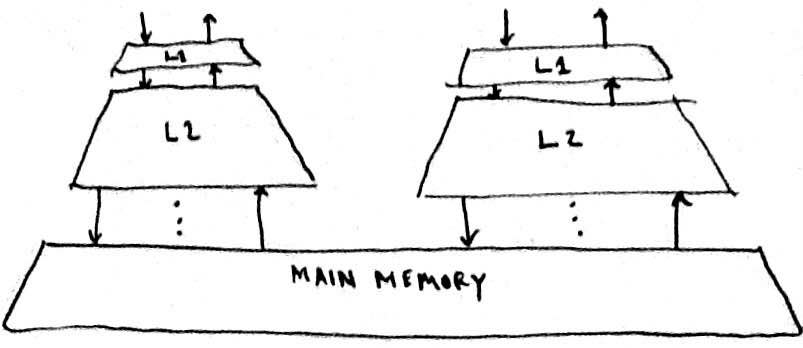
Such hierarchies introduce race-conditions that occurs due to caching. More specifically, consider two functions running in different threads on different cores on a multi-core processor:
#include <stdio.h>
int a = 0;
int b = 0;
void thread_one(){
b = 1;
printf("a = %i\n",a);
}
void thread_two(){
a = 2;
printf("b = %i\n",b);
}
What are the possible outputs?
thread_one prints before thread_two assigns
0
1
thread_two prints before thread_one assigns
0
2
Both assign, thread_one prints then thread_two prints
2
1
Both assign, thread_two prints then thread_one prints
1
2
Main memory is inconsistent due to memory writes not cascading downward completely
Any of the earlier given outputs or, the more surprising output,
0
0
Caching can break useful abstractions.
I found the last output example surprising and unsatisfactory brought it to my attention. Most programming languages were designed with respect to the Von Neumann computer architecture model. Specifically, that if a write of $2$ to address $A$ occurs before a read of address $A$, then the read will return a value of $2$ assuming know other writes to $A$ occurred between these operations. In a single-core processor, all is well, but in a multi-core processor we are forced to understand some aspect of how caching works. The exposure of caching details above the Von Neumann model has resulted in bolt-on ad hoc adjustments such as ~volatile~. As someone concerned with programming language design this is annoying. It seems like we must construct new models and programming languages to recover elegant predictable behavior following from intuitive models on multi-core processors.